About
This is the Deep Sea AI back-end software stack. This collection of software manages the processing, storage, and access to deepsea video track data which can be used as an AI-powered augmentation to your existing annotation process.
Using the AWS cloud ecosystem, we apply state-of-the-art machine learning techniques and scaleable computing to cost-effectively process video in the cloud. Important this is not a "pure" cloud system; cloud is only used for managing compute resources. Video and its associated video track data have limited life in the cloud to control cost.
This code is under active development.
There are two components in the back-end: a database to store machine learning track data, and an elastic processing cluster to process video efficiently.
This design currently uses the Video Asset Manager VAM service in the MBARI Media Management (M3) to manage video assets. Use of a VAM is optional, but it is highly recommended. See M3 Quickstart for installation instructions.
Quick Start
See quick start instructions to setup.
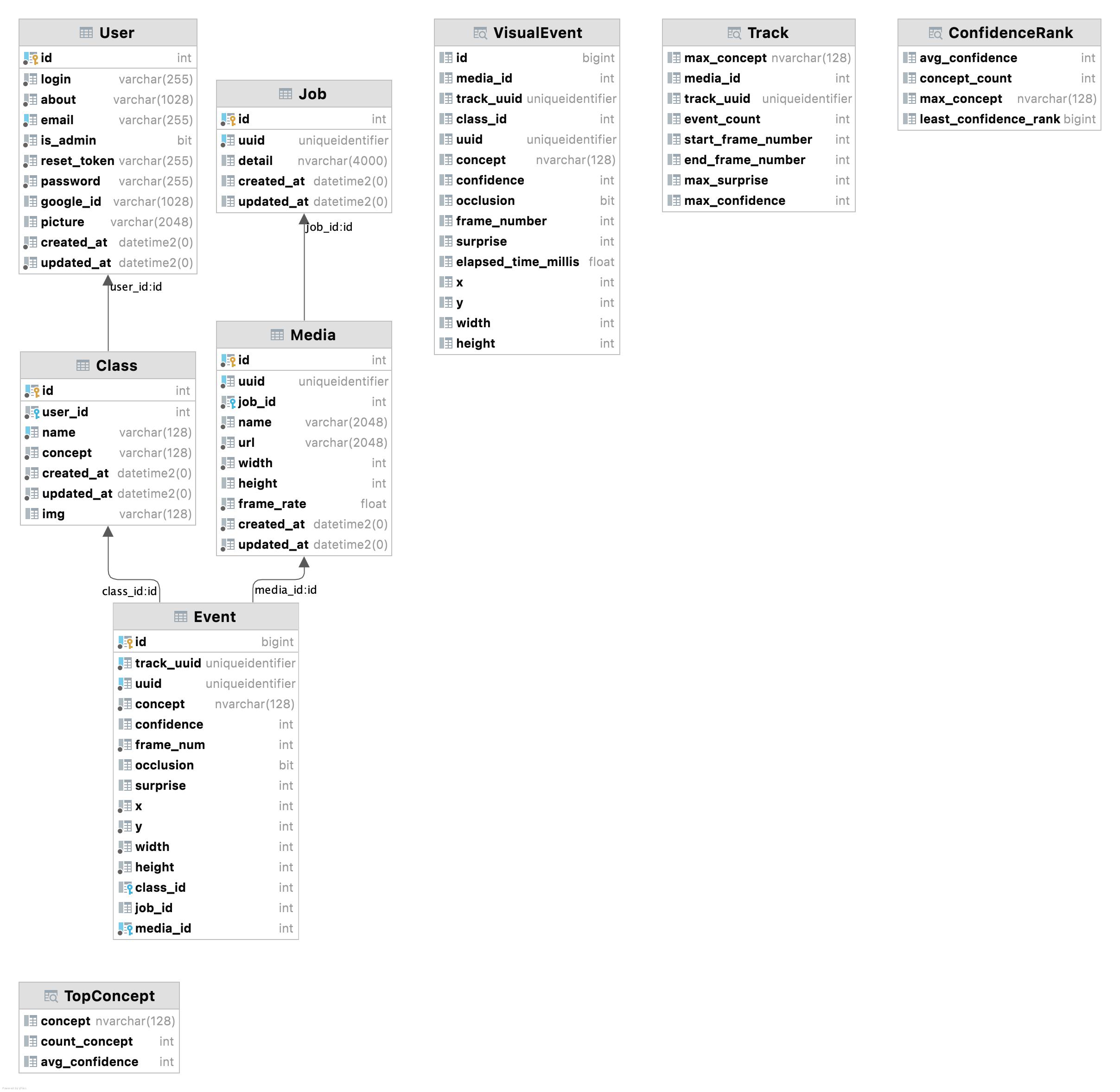
Database
The database technology stack includes GraphQL, Nexus,Prisma, and a (default) Postgres database.
- Nexus is a library that helps create type-safe GraphQL APIs
- GraphQL "is an open-source data query and manipulation language for APIs, and a runtime for fulfilling queries with existing data. GraphQL was developed internally by Facebook in 2012 before being publicly released in 2015."wikipedia
- Prisma is a next-generation ORM that simplifies databases for application developers
- Redis task queues to execute in the background using workers
- Postgres is a free relational database. Microsoft SQL Server is also supported and is the preferred database at MBARI for its performance. SQL Server requires a paid license.
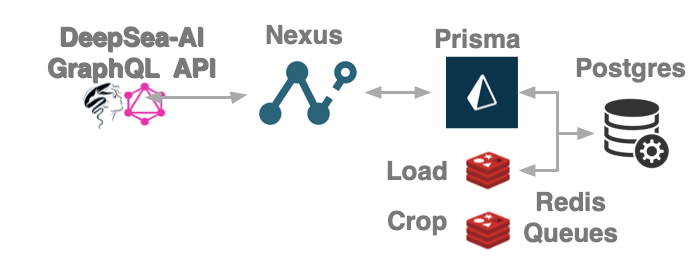
In development mode you can interact with the database in a web based graphical interactive tool.
GraphiQL Database API
After installation open http://localhost:4000/graphql to explore. Check-out example queries and mutations.
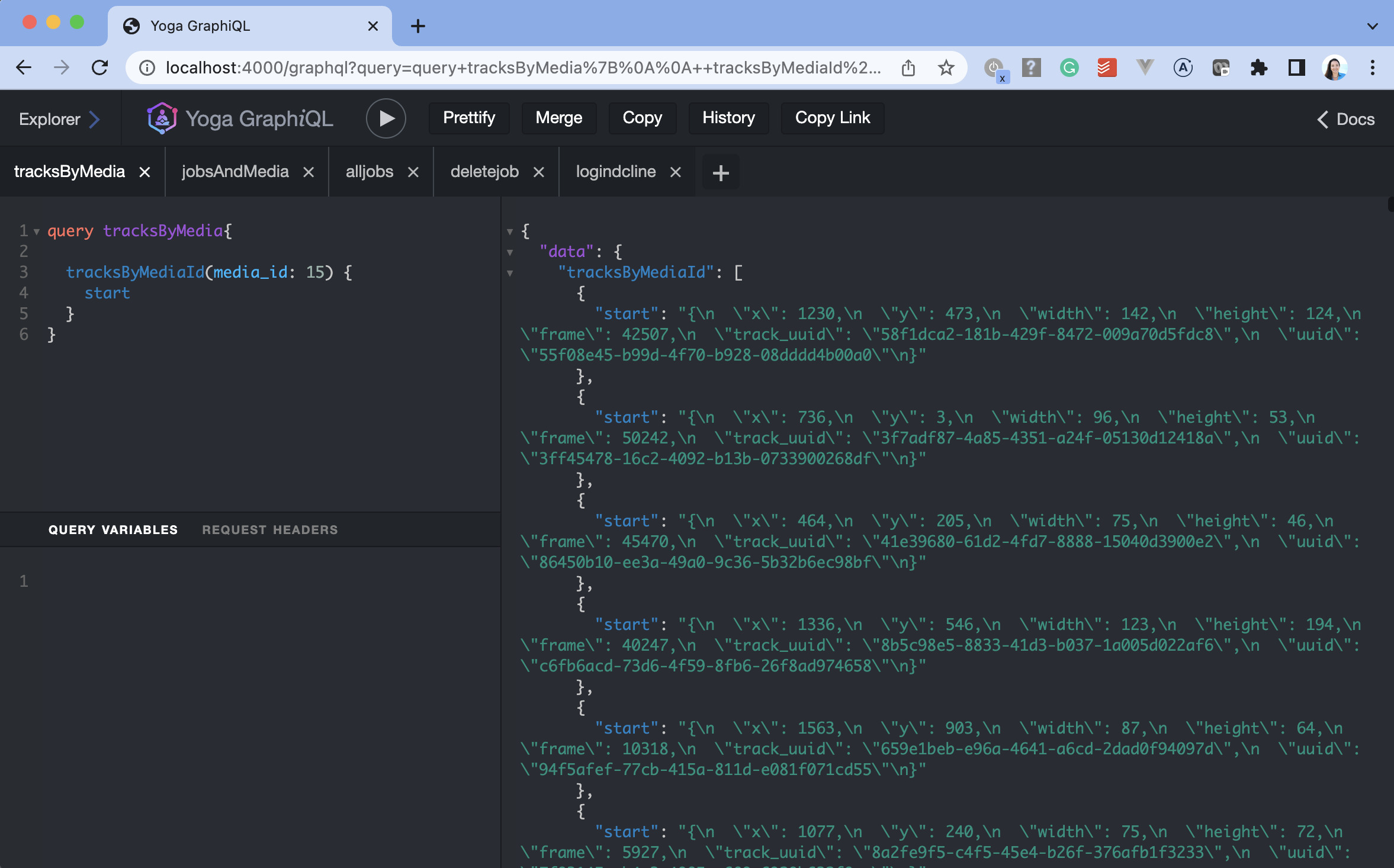
Processing
The processing technology uses the AWS Elastic Container Service with an architecture that includes a SQS messaging queue to start the processing. Simply upload a video to an S3 bucket then submit a job with the location of that video to the queue to start processing. The result is returned to a S3 bucket and the video is optionally removed to reduce storage cost.
[click image below to see larger example]
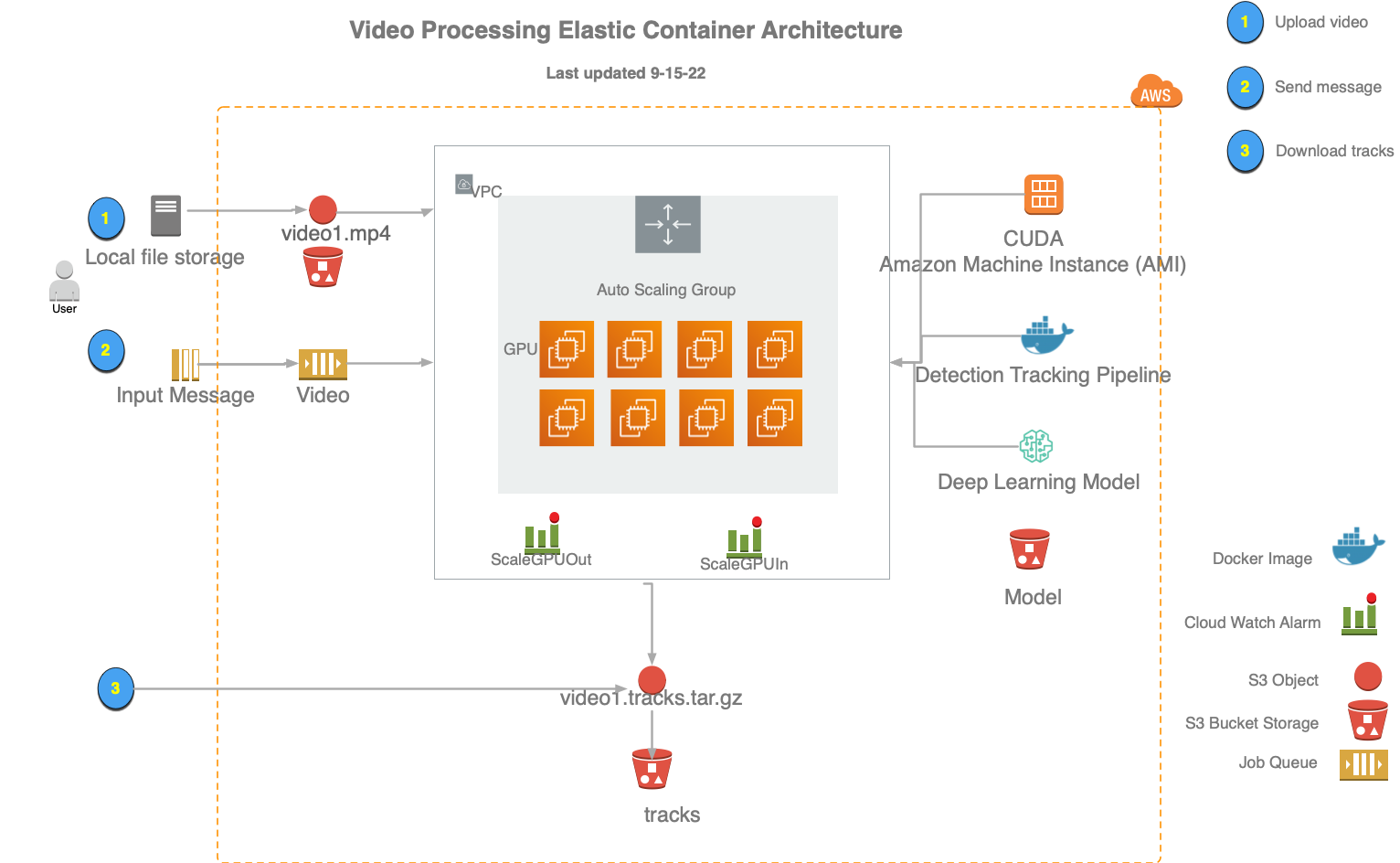
Schema
The current database schema
[click image below to see larger example]